











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


零基础学习网络爬虫知识(一)
更新时间:2016年09月29日16时09分 来源:传智播客 浏览次数:
1、网络爬虫的定义
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
2、网络爬虫与浏览器相似之处
网络爬虫的抓取过程可以理解为 模拟浏览器操作的过程。
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示您选择的网络资源。这里所说的资源一般是指 HTML 文档,也可以是 PDF、图片或其他的类型。
资源的位置由用户使用 URI(统一资源标示符)指定。
浏览器解释并显示HTML文件的方式是在HTML和CSS规范中指定的。这些规范由网络标准化组织 W3C(万维网联盟)进行维护。
3、网络爬虫抓什么
一般来讲,抓取的内容主要来源于网页,目前,随着这几年移动互联网的发展,越来越多信息来源于移动互联网App、H5等,所以爬虫就不止局限于一定要抓取解析网页,还有移动互联网app、H5等的网络请求进行抓取
对网络爬虫而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值。
4、了解网络请求
网络爬虫以HTTP、HTTPS请求为主,读取网页内容,提取有用的价值,内容一般分为两部分,非结构化的文本,或结构化的文本。
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
4.1 HTTP请求的方法
HTTP/1.1协议中共定义了八种方法(有时也叫“动作”)来表明Request-URI指定的资源的不同操作方式:
OPTIONS
返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送'*'的请求来测试服务器的功能性。
HEAD
向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
GET
向特定的资源发出请求。注意:GET方法不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
POST
向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT
向指定资源位置上传其最新内容。
DELETE
请求服务器删除Request-URI所标识的资源。
TRACE
回显服务器收到的请求,主要用于测试或诊断。
CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
4.2 HTTP响应的代码
服务器程序响应的第一行叫状态行。状态行以HTTP版本号开始,后面跟着3位数字表示响应代码,最后是易读的响应短语。根据第一位可以把响应分成5类:
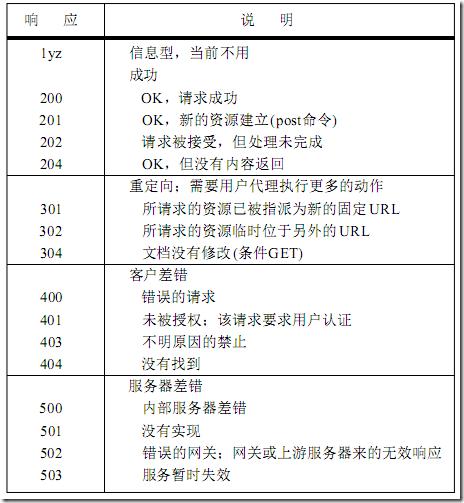
图1、HTTP响应代码
4.3实例演示
我们用浏览器去访问https://www.baidu.com, 在浏览器中打开开发人员工具(F12),F12 开发人员工具是可帮助生成和调试网页的一套工具。按下F12按钮调出开发者工具界面,点击第一行“Network”选项卡,可见下方以详细信息的方式列举出了网页中的元素。
找到我们请求的链接https://www.baidu.com,响应消息的状态行是:HTTP/1.1 200 OK,其中HTTP/1.1对应版本号、200对应response-code;如下图2所示

图2、GET / HTTP/1.1请求的响应消息
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
